Abstract
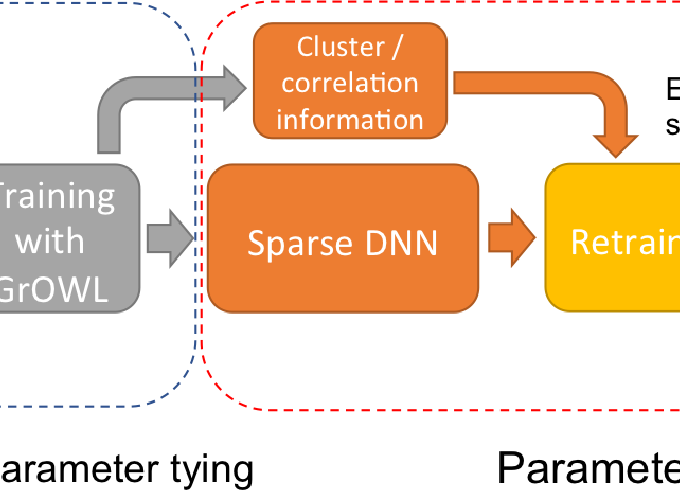
Deep neural networks (DNNs) may contain millions, even billions, of parameters/weights, making storage and computation very expensive and motivating a large body of work aimed at reducing their complexity by using, e.g., sparsity-inducing regularization. Parameter sharing/tying is another well-known approach for controlling the complexity of DNNs by forcing certain sets of weights to share a common value. Some forms of weight sharing are hard-wired to express certain invariances; a notable example is the shift-invariance of convolutional layers. However, other groups of weights may be tied together during the learning process to further reduce the network complexity. In this paper, we adopt a recently proposed regularizer, GrOWL (group ordered weighted L1), which encourages sparsity and, simultaneously, learns which groups of parameters should share a common value. GrOWL has been proven effective in linear regression, being able to identify and cope with strongly correlated covariates. Unlike standard sparsity-inducing regularizers (e.g., L1 a.k.a. Lasso), GrOWL not only eliminates unimportant neurons by setting all their weights to zero, but also explicitly identifies strongly correlated neurons by tying the corresponding weights to a common value. This ability of GrOWL motivates the following two-stage procedure: (i) use GrOWL regularization during training to simultaneously identify significant neurons and groups of parameters that should be tied together; (ii) retrain the network, enforcing the structure that was unveiled in the previous phase, i.e., keeping only the significant neurons and enforcing the learned tying structure. We evaluate this approach on several benchmark datasets, showing that it can dramatically compress the network with slight or even no loss on generalization accuracy.